



11月10日,维亚生物联手大零号湾·国盛健康云城同步线上线下成功举办“医药大数据赋能创新药研发”沙龙。众多行业大咖、业界先锋聚集于此,从更大视野、更多维度探讨医药大数据以及AI技术在小分子药物领域的颠覆与突破,共同展望小分子药物下一个黄金时代。
大零号湾·国盛健康云城副总经理王宝玉女士、总经理助理赵丽岗博士和招商运营部总监朱正银先生出席本次沙龙。活动伊始,朱正银先生首先发表了开场致辞。随后正式进入本次活动的主题分享环节。下面整理了各位嘉宾的部分精彩观点以饕读者。错过本期直播的伙伴,可点击「此处」观看,或者关注“维亚生物”视频号了解本期完整版视频回放。
DNA编码分子库的大数据
能否创造FIC药物研发的新机遇?

夏冰博士 维亚生物副总裁
1992年,诺贝尔生理与医学奖获得者Sydney Brenner和Richard Lerner率先提出DNA编码化合物库(DNA Encoded Library,DEL)这一概念。此后,DEL技术经历十多年的飞跃发展,随着研究成果的不断显现,现已成为药物发现的新兴支柱之一。夏冰博士由此出发全面介绍了DEL技术的研发步骤,从建库开始、到亲和力筛选、高通量测序、数据分析、合成不带DNA的化合物直至苗头化合物确证,着重讲述了建库所用的合成方法“Split&Pool”、亲和力筛选的实验步骤及它们所带来的优势。他表示,与传统筛选方法相比,DEL库容量巨大、分子多样性好,又兼具研发周期短、成本低等优势,还可以筛选某些复杂的蛋白靶点。此外,还可以将CADD/AIDD融入到DEL技术中,并结合开发多种DNA兼容化学反应,进一步实现DEL技术的快速、有效、增殖效应。随后,他还列举多个成功案例阐述了DEL技术在FIC新药发现方面的广泛应用。最后,夏冰博士指出,维亚近期推出的、也是由他领导的V-DEL技术平台,将搭建多种类型的高质量DEL库、以高效的筛选方式,通过与SBDD/FBDD、ASMS、SPR等技术平台的整合,及与整个维亚一站式药物研发平台的融合,提供从靶点蛋白生产、DEL分子库构建、亲和筛选、活性化合物定制合成、生物试验验证开发等基于DEL技术药物研发的全套的、差异化的服务。
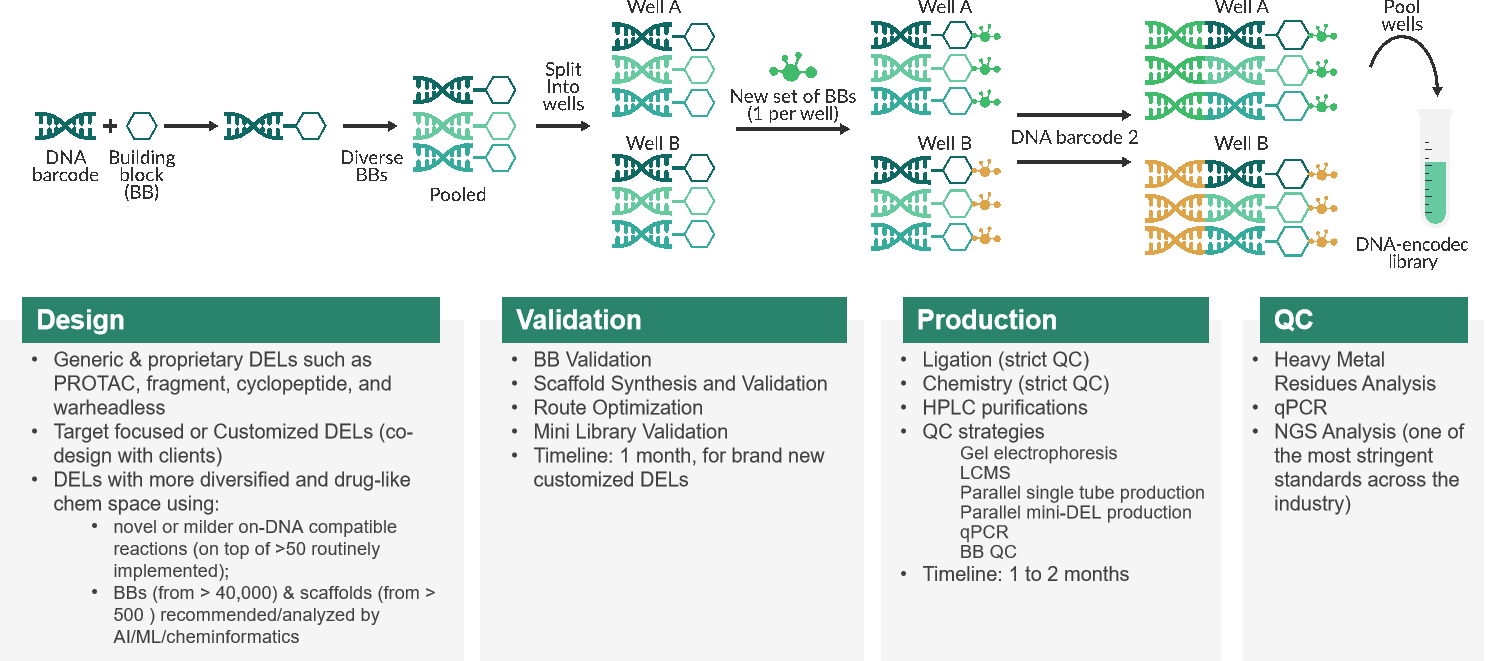
(高质量的V-DEL分子库搭建流程)
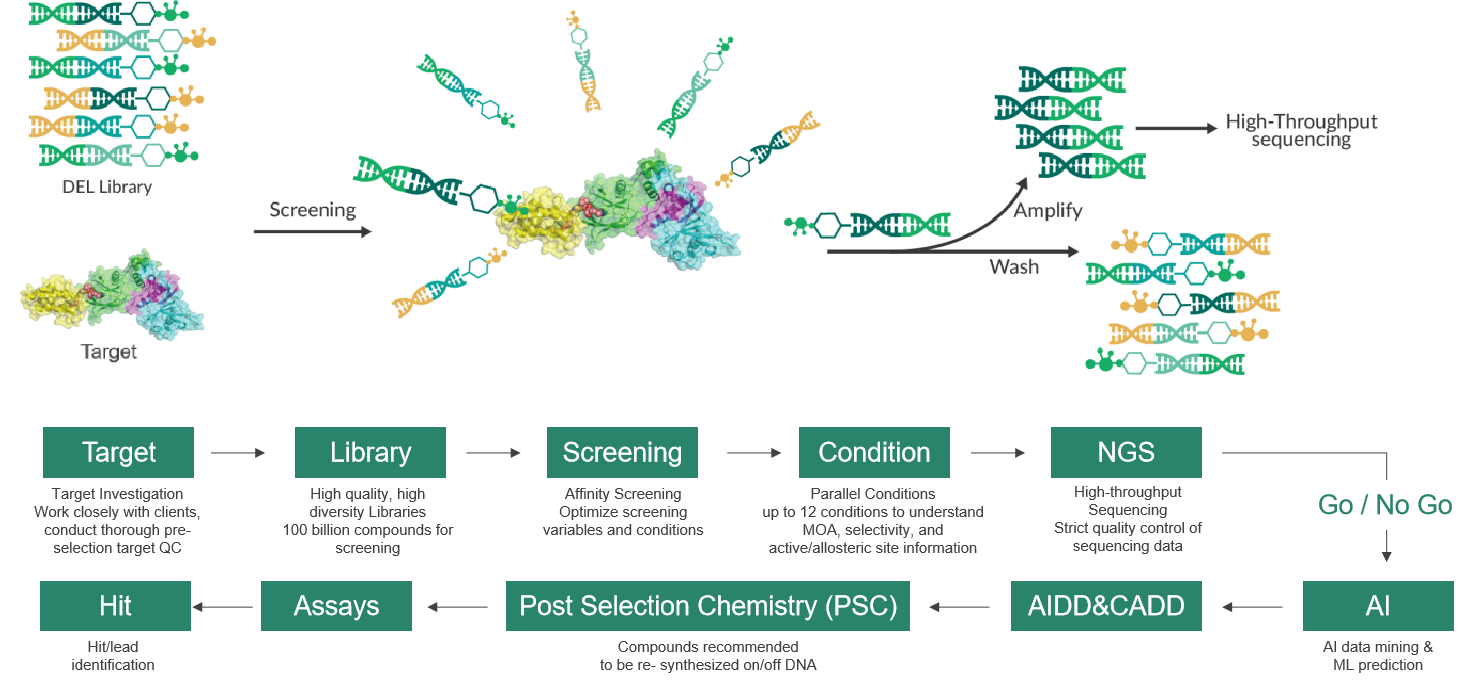
(高效的V-DEL筛选流程)
基于几何深度学习的蛋白质设计与改造

周冰心博士 上海交通大学自然科学研究院助理研究员
周冰心博士从计算机科学的角度出发介绍了近一年来她在蛋白质设计与改造方面的研究进展及相应的一些思考。她首先介绍了合成生物学中的蛋白设计任务,全面讲述了人工智能辅助方法与传统实验方法的对比、蛋白质预测、蛋白质结构表达、结构数据编码器、生物数据的图表示方法及图表示学习。随后,她进一步分享了从湿实验的角度,将蛋白质建立成图并进行深度学习算法之后所获得研究成果,通过列举多蛋白、多需求改进案例阐述了轻量蛋白质改进工具的应用。同时,她还讲述了另一个基于图神经网络的框架——蛋白质序列从头设计的研究成果,研究团队采用了类似图像生成原理的扩散概括生产方法,对限制性核酸内切酶进行了设计,与现有RFdiffusion、ProGen相比,通过她们方法获得的全新蛋白质的序列长度达到800,而后两者分别为100-400、140,且活性优于野生型的成功率为74%,而后两者为10-20%、40%,最后,她还从剪切活性和热稳定性、隐藏序列信息推理、多样性VS高序列恢复性等角度对比了和野生型蛋白的差别,进一步展现了其基于几何深度学习模型的蛋白设计与改造的优越性。
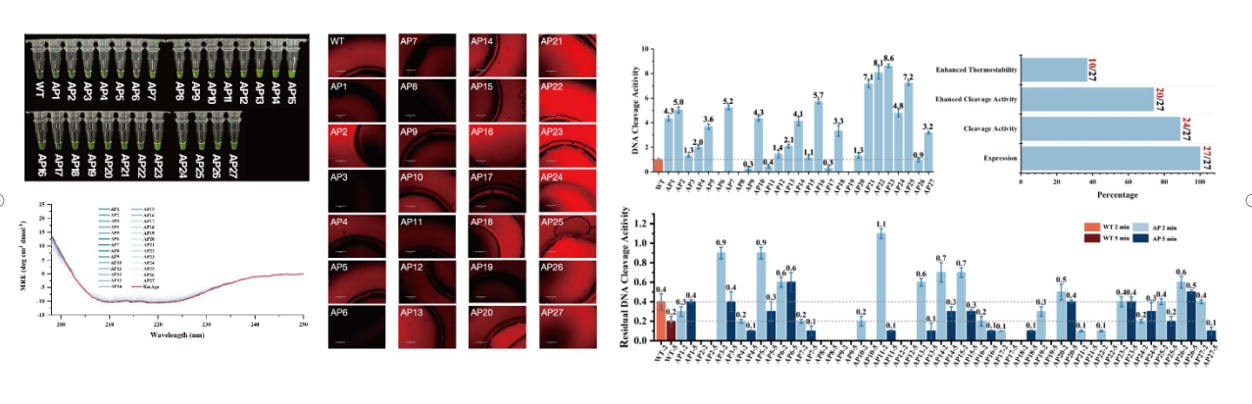
(剪切活性和热稳定性对比案例)
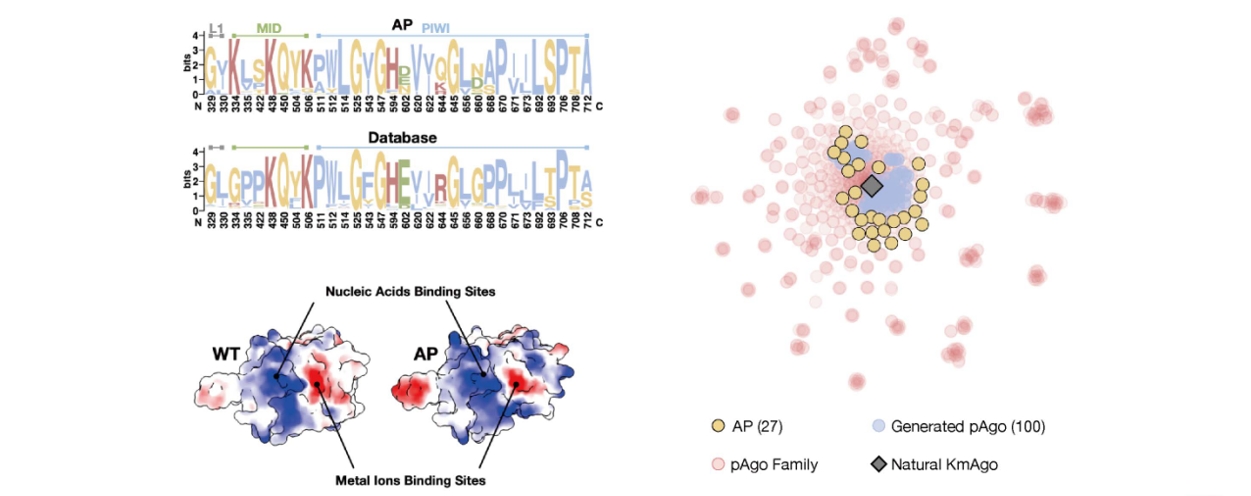
(隐藏序列信息推理案例)
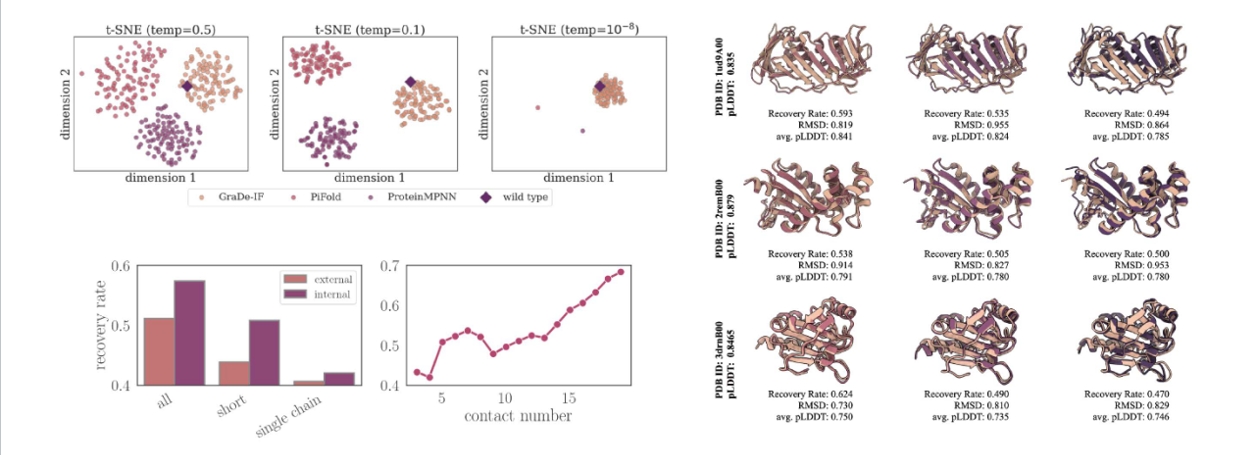
(多样性VS高序列恢复性案例)
圆桌讨论
医药研发新范式,大数据+AI如何赋能新药研发?

(从左往右:维亚生物计算化学高级主任钱玥博士、子瞻医药创始人兼CEO闵贞博士、智峪生科CEO王晟博士、深势科技对外合作总监林诗语女士、英矽智能高级业务拓展总监王珏博士)
Q1:当今的AI药物研发主要有三种商业模式:AI-biotech、AI-CRO和AI管线。随着大数据的不断发展,第四种商业模式也开始崭露头角,即基于大数据的公司,例如知名的AI制药公司Recursion。各位认为第四种商业模式和前三种模式的区别是什么,它又是如何去助力药物研发的呢?
闵贞博士:Recursion的宣传语“Decoding Biology To Radically Improve Lives”是他非常认同的,Recursion回归到了做药最根本的问题——从生物学的角度去回答药理、药效、毒理及对疾病的影响。同时,他认为Recursion的特别之处在于它打通了从wet lab到dry lab的界限。另外一点,Recursion还非常注重数据的相关性,尤其是化学平台与生物学平台产生的数据必须要有很强的相关性。
王晟博士:大家都知道,数据对AI来说至关重要。因为有了数据,科学家们才能构建这些模型,产生全新的理解数据的范式,从而进一步推动整个科学社会的进步与发展。尤其是现今已经进入到生物时代,比方说生物技术、生物工程、AI制药、CADD及合成生物学等领域都积累了大量的数据, 如何去理解这些多模态的数据?去开发相应的、简单的理解方式去建模,是AI的一大挑战。克服了这一难题,或许能迎来AI的第三次革命。
林诗语女士:数据对于AI确实是非常重要的。经常会碰到客户问,如果做AI数据不够了怎么办,尤其是在生物医药领域会有一些数据非常的稀少,甚至可能是掌握在极少数比较大的制药公司手中,这是行业普遍存在的一大问题,同样也是前三种模式面临的难题。Recursion提供了一个非常巧妙的解题思路,另外也有美国、加拿大的研发团队试图通过几何深度学习、合成数据、零样本的机器学习等多个方法来解决数据稀缺的问题。这些都是非常有意义的探索与方向。
王珏博士:无论是做AI的,还是做科研的,大家都知道数据的难能可贵,而实现这些的前提是大量的成本投入,就好比说Recursion也是耗费大量的资金进行海量数据积累,但这并适用于每一家公司去复制。对于Biotech来说,首先要清楚自己的技术特点,擅长的领域,还要综合考虑公司的布局及商业模式能给公司带来的长远的发展空间。以英矽智能为例,它一开始是通过算法与很多科研机构及大药企合作,来汲取宝贵的数据和合作经验,随着算法的逐步成熟,再将其落地成软件并以此为客户直接提供软件服务,同时还可将它应用到自有管线中以进行管线的对外授权。
Q2:最近,DeepMind推出新版的AlphaFold模型,也就是AlphaFold 3,据说它不再局限于蛋白质折叠,还能够在配体、蛋白质、核酸以及翻译后修饰等方面生成高度精确的结构预测,并且该系统已用于药物设计。各位觉得这样一个工具存在的最大特点是什么?有没有什么限制?及对药物设计本身的指导作用?
王晟博士:AlphaFold 3可以实现从之前的只能做一个蛋白,到现在能够预测蛋白与任一生物分子之间的相互作用,这可以称得上是一个伟大的跨越。熟悉AlphaFold 2的人应该都知道,这一工具的核心底层逻辑是共折叠,了解了这一逻辑后再去扩散到蛋白与蛋白、蛋白与短肽、蛋白与核酸是一个非常自然的过程。对于AlphaFold2来说,理念是一方面,它的强大之处还在于工程能力、算力和基础建设。另外,顶尖人才招揽也是AlphaFold2成功的核心驱动力。
王珏博士:AlphaFold刚推出时,对于AI制药领域带来震撼就像一次地震。对于一个没有很好的结构信息的靶点,通常情况下,大家可能会尝试做DEL、高通量筛选等,但如果是在有一个准确的结构信息的情况下,就可以通过AI进行分子生成,这给业界带来了一个全新的路径。并且,结构的准确度越高,所生成有活性分子的机率也是越高的,也必会给整个药物研发带来助益。
Q3:与传统药物设计相比,CADD/AIDD辅助的药物设计有何特别之处,它们提供新颖性在哪里,及怎么和一个有经验的药化专家区别开?
王珏博士:一开始大家对AI寄予了过高的期望,想象它可能会给行业带来颠覆式的影响,但从实际落地来讲,它其实更多的是帮助科学家的工具,就目前视野可看到的时间线内,还无法实现取代这一动作。所以英矽智能会让科学们充分使用这一工具来进行新药研发的加速与赋能。而AI学习的基础又来源于科学们积累的数据与知识,所以在AI应用过程中所产生的结果会与科学家的相似,或者说符合知识逻辑的生成。
林诗语女士:CADD/AIDD在近几年仍然是一个辅助工具,可以很好地帮助到新入行的科研人员。而它的新颖性一方面体现在分子设计中,为科学家提供更全面、更广阔的思路;另一方体现在活性的验证上,计算可以和实验相结合,提高决策的效率与实验质量。
王晟博士:CADD/AIDD在整个制药路径中可能最多只占15%,它可以帮助大家找到先导化合物或者苗头化合物,但这也仅仅是一个分子,离成为可以口服的药物还有很长一段距离,还需要进行一系列体内实验、体外实验、动物实验、毒理实验、临床试验等,这每一步都牵涉了很多的时间、人员与金钱,这些都是制药工业中AI很难触及到的大山。
Q4:现在药物设计中使用的模型还需要大量的人工干预和专家参与,针对这一现象,各位觉得这一类AI工具有没有哪些突破口来真正实现智能化?
闵贞博士:目前AI发展的一大瓶颈在于数据的缺乏,一方面是生物学数据的缺乏,一方面是化学数据的缺乏。以Recursion为例,截止到今年9月30号,它已经通过上亿的实验,积攒了23PB的数据,筛选了600万个分子,从而实现海量数据的积累,并利用这些数据落实AI工具的应用。所以高质量数据是训练AI的前提和基础。
Copyright © 维亚生物 All Rights Reserved. 沪ICP备19036061号